
Large Language Models (LLMs) are pivotal in advancing natural language processing tasks because of their profound understanding and generation capabilities. These models are always refined to higher comprehend and execute complex instructions across varied applications. Despite the numerous progress on this field, a persistent issue stays: LLMs often produce outputs that only partially adhere to the given instructions. This misalignment may end up in inefficiencies, especially when the models are applied to specialized tasks requiring high accuracy.
Existing research includes fine-tuning LLMs with human-annotated data, as demonstrated by models like GPT-4. Frameworks corresponding to WizardLM and its advanced iteration, WizardLM+, enhance instruction complexity to enhance model training. Studies by Zhao et al. and Zhou et al. affirm the importance of instruction complexity in model alignment. Moreover, Schick and Schütze advocate for automating synthetic data generation, leveraging LLMs’ in-context learning capabilities. Techniques from knowledge distillation, introduced by Hinton et al., also contribute to refining LLMs for specific instructional tasks.
Researchers at Google Cloud AI have developed CodecLM, an modern framework designed to align LLMs with specific user instructions through tailored synthetic data generation. CodecLM distinguishes itself by utilizing an encode-decode mechanism to provide highly customized instructional data, ensuring that LLMs perform optimally across diverse tasks. This system leverages Self-Rubrics and Contrastive Filtering techniques, enhancing the relevance and quality of synthetic instructions and significantly improving the models’ ability to follow complex instructions accurately.
CodecLM employs an encode-decode approach, transforming initial seed instructions into concise metadata that captures essential instruction characteristics. This metadata then guides the generation of synthetic instructions tailored to specific user tasks. To boost instruction quality and relevance, the framework utilizes Self-Rubrics so as to add complexity and specificity and Contrastive Filtering to pick out essentially the most effective instruction-response pairs based on performance metrics. The effectiveness of CodecLM is validated across several open-domain instruction-following benchmarks, demonstrating significant improvements in LLM alignment in comparison with traditional methods without counting on extensive manual data annotation.

CodecLM’s performance was rigorously evaluated across several benchmarks. Within the Vicuna benchmark, CodecLM recorded a Capability Recovery Ratio (CRR) of 88.75%, a 12.5% improvement over its nearest competitor. The Self-Instruct benchmark achieved a CRR of 82.22%, marking a 15.2% increase from the closest competing model. These figures confirm CodecLM’s effectiveness in enhancing LLMs’ ability to follow complex instructions with higher accuracy and alignment to specific user tasks.
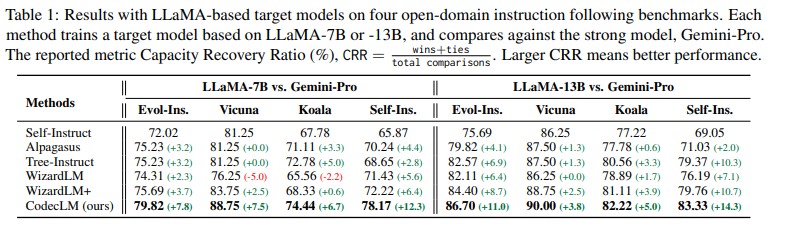
In conclusion, CodecLM represents a major advancement in aligning LLMs with specific user instructions by generating tailored synthetic data. By leveraging an modern encode-decode approach, enhanced by Self-Rubrics and Contrastive Filtering, CodecLM significantly improves the accuracy of LLMs following complex instructions. This improvement in LLM performance has practical implications, offering a scalable, efficient alternative to traditional, labor-intensive methods of LLM training and enhancing the models’ ability to align with specific user tasks.
Take a look at the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our newsletter..
Don’t Forget to affix our 40k+ ML SubReddit
Need to get in front of 1.5 Million AI Audience? Work with us here
![]()
Nikhil is an intern consultant at Marktechpost. He’s pursuing an integrated dual degree in Materials on the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who’s at all times researching applications in fields like biomaterials and biomedical science. With a robust background in Material Science, he’s exploring latest advancements and creating opportunities to contribute.